Ahora que ya hemos analizado en profundidad cada atributo de nuestro dataset, vamos a necesitar algunos gráficos que nos den ideas sobre cómo continuar nuestro análisis.
Para ello, vamos a utilizar la herramienta ggplot2, la cual nos va a permitir realizar los gráficos complejos de los que estamos hablando.
ggplot2: Create Elegant Data Visualisations Using the Grammar of Graphics
A system for ‘declaratively’ creating graphics, based on “The Grammar of Graphics”. You provide the data, tell ‘ggplot2’ how to map variables to aesthetics, what graphical primitives to use, and it takes care of the details.
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
datos <-read_csv("Data/train.csv")
Rows: 576 Columns: 12
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (12): profile pic, nums/length username, fullname words, nums/length ful...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
2.1 Pre-procesado
Para hacer este trabajo más fácil, vamos a realizar un preprocesado de los datos primero. Vamos a convertir todos los atributos que son discretos a factores.
Nuestros atributos discretos son binarios, solo tienen o bien Sí o No. Vamos a emplear ahora los gráficos para poder encontrar alguna relación entre las variables y, sobre todo, lo que más nos interesa, si alguna tiene relación con las cuentas de spam.
2.2 Comparación de la cantidad de publicaciones entre cuentas privadas y públicas
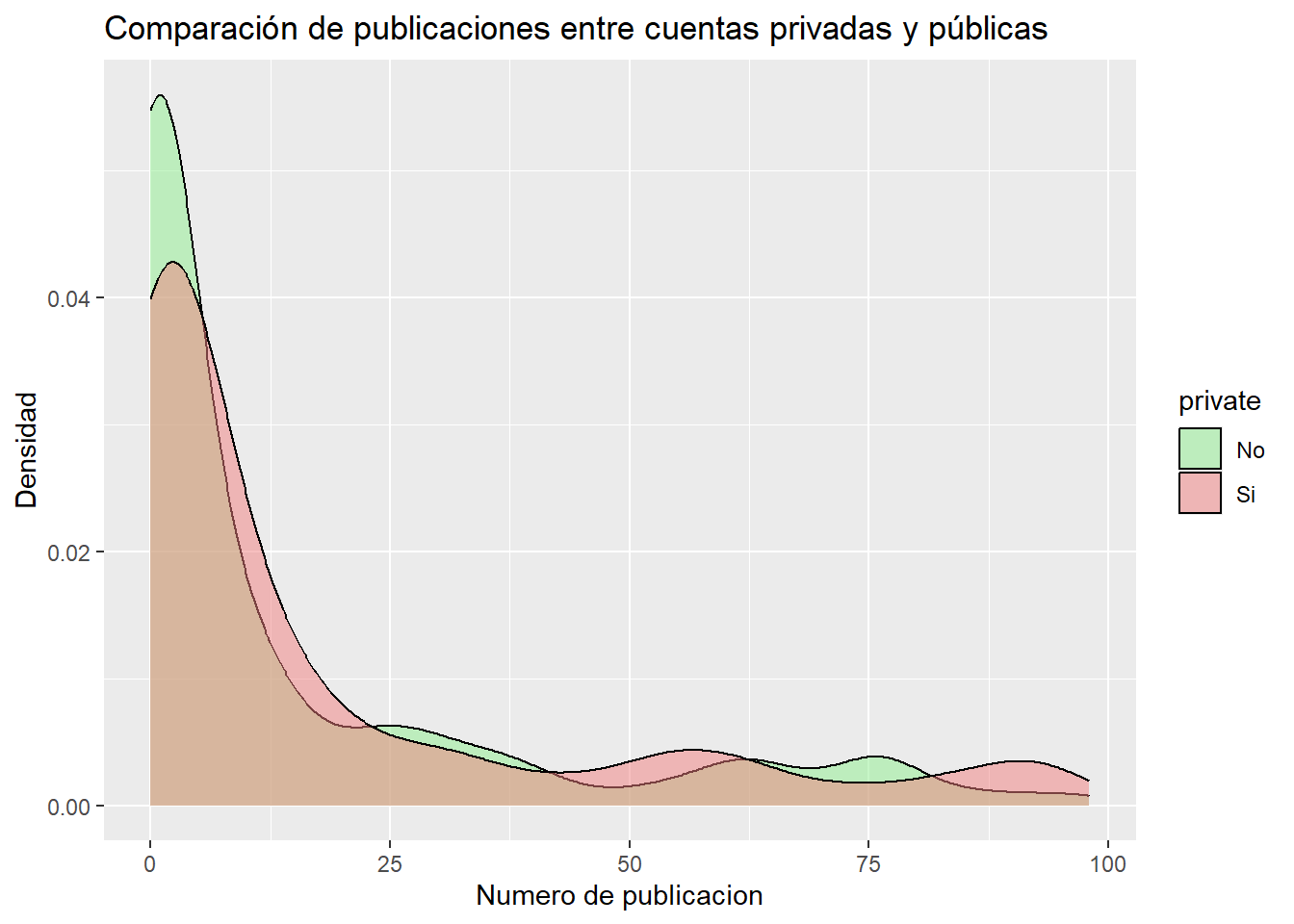
Para ver cómo se comportan ambos tipos de usuarios, vamos a empezar analizando el número de publicaciones entre los usuarios con cuentas públicas y con cuentas privadas. Para ello, vamos a ver las densidades utilizando geom_density:
posts_filtrados <- datos_refinados %>%filter(`#posts`<100)ggplot(data = posts_filtrados, aes( x =`#posts`,fill = private)) +geom_density(alpha =0.5) +labs(title ="Comparación de publicaciones entre cuentas privadas y públicas",x ="Numero de publicacion",y ="Densidad") +scale_fill_manual(values =c("lightgreen", "lightcoral"))
Vemos que en ambos casos, nuestra gráfica es similar, lo que sugiere que el número de publicaciones no depende de si la cuenta es privada o pública.
Sin embargo, lo que realmente nos interesa es encontrar relaciones para intentar determinar si una cuenta es de un spammer o de una persona real. Por lo tanto, vamos a centrarnos en comparar los atributos con el atributo “spam”.
2.3 Relación entre visibilidad del perfil y cuentas fake
Como nos interesa buscar las cuentas de spam, vamos a ver si la visibilidad del perfil (cuenta privada o pública) tiene algo que ver:
ggplot(datos_refinados, aes(x =`fake`, y =`private`)) +geom_count(color ="blue", alpha =0.6) +scale_size_area()+labs(title ="Relación entre visibilidad del perfil y si es spam", x ="Cuenta fake", y ="Cuenta privada")+theme_minimal()
Utilizando geom_count con dos variables discretas, en este caso si un perfil es privado o no y si un perfil es falso o no, no podemos extraer mucha información relevante ya que vemos que hay aproximadamente un número similar de cada combinación.
2.4 Relación entre tener foto de perfil y ser cuenta falsa.
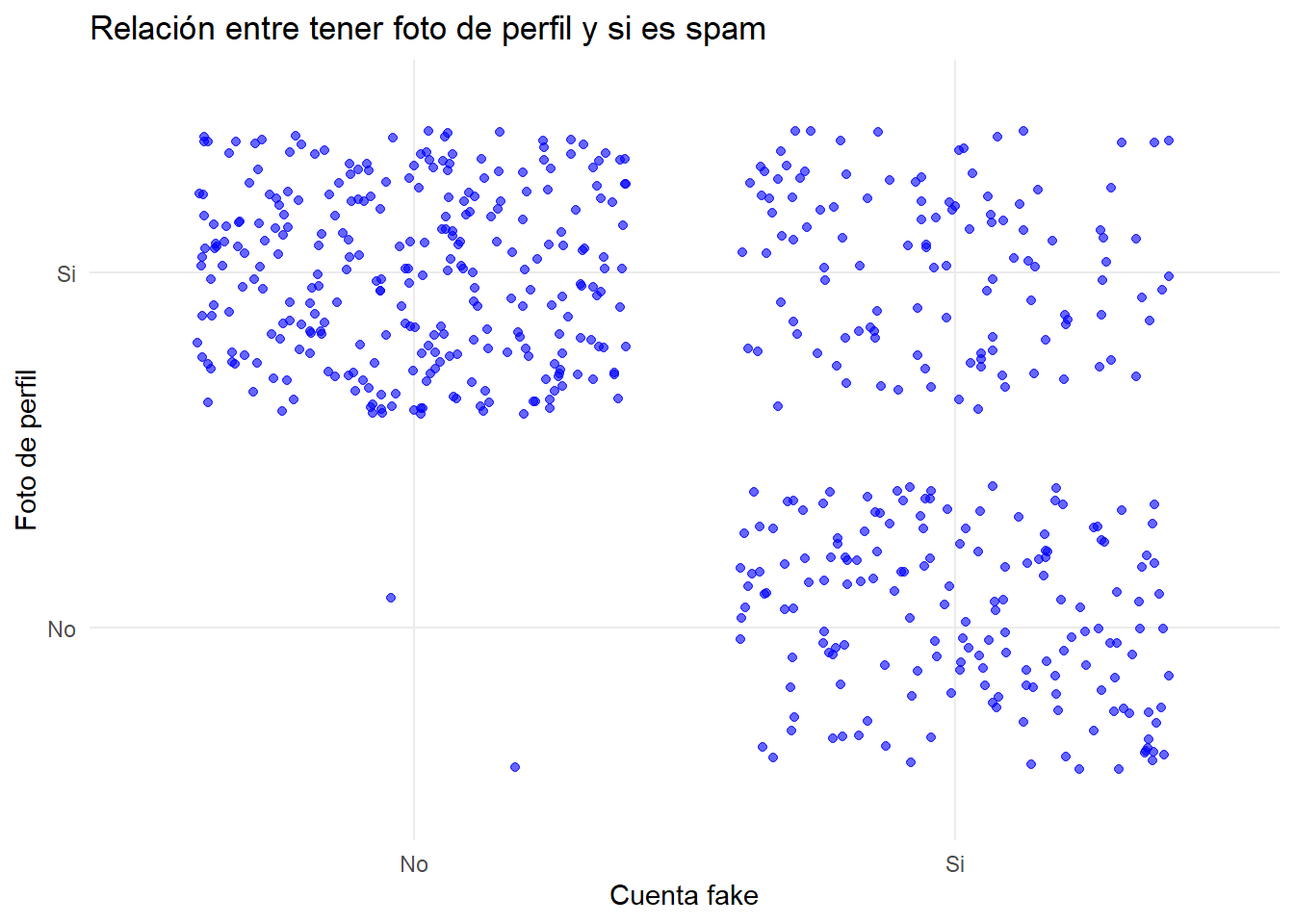
Al igual que antes, vamos a comprobar dos variables discretas, por lo que el aspecto del gráfico será diferente. Vamos a comprobar si tener o no foto de perfil tiene algo de relación con ser un spammer.
ggplot(datos_refinados, aes(x =`fake`, y =`profile pic`)) +geom_jitter(color ="blue", alpha =0.6) +scale_size_area()+labs(title ="Relación entre tener foto de perfil y si es spam", x ="Cuenta fake", y ="Foto de perfil")+theme_minimal()
Hemos obtenido un resultado interesante, donde vemos que las cuentas reales, todas menos 2, tienen foto de perfil puesta, mientras que las cuentas falsas tienen más o menos un mismo número con foto de perfil y sin foto de perfil. Estos datos, combinados con otros que vamos a obtener más adelante, nos pueden ayudar a diferenciar cuentas reales de falsas.
2.5 Relación entre número de publicaciones y cuentas falsas.
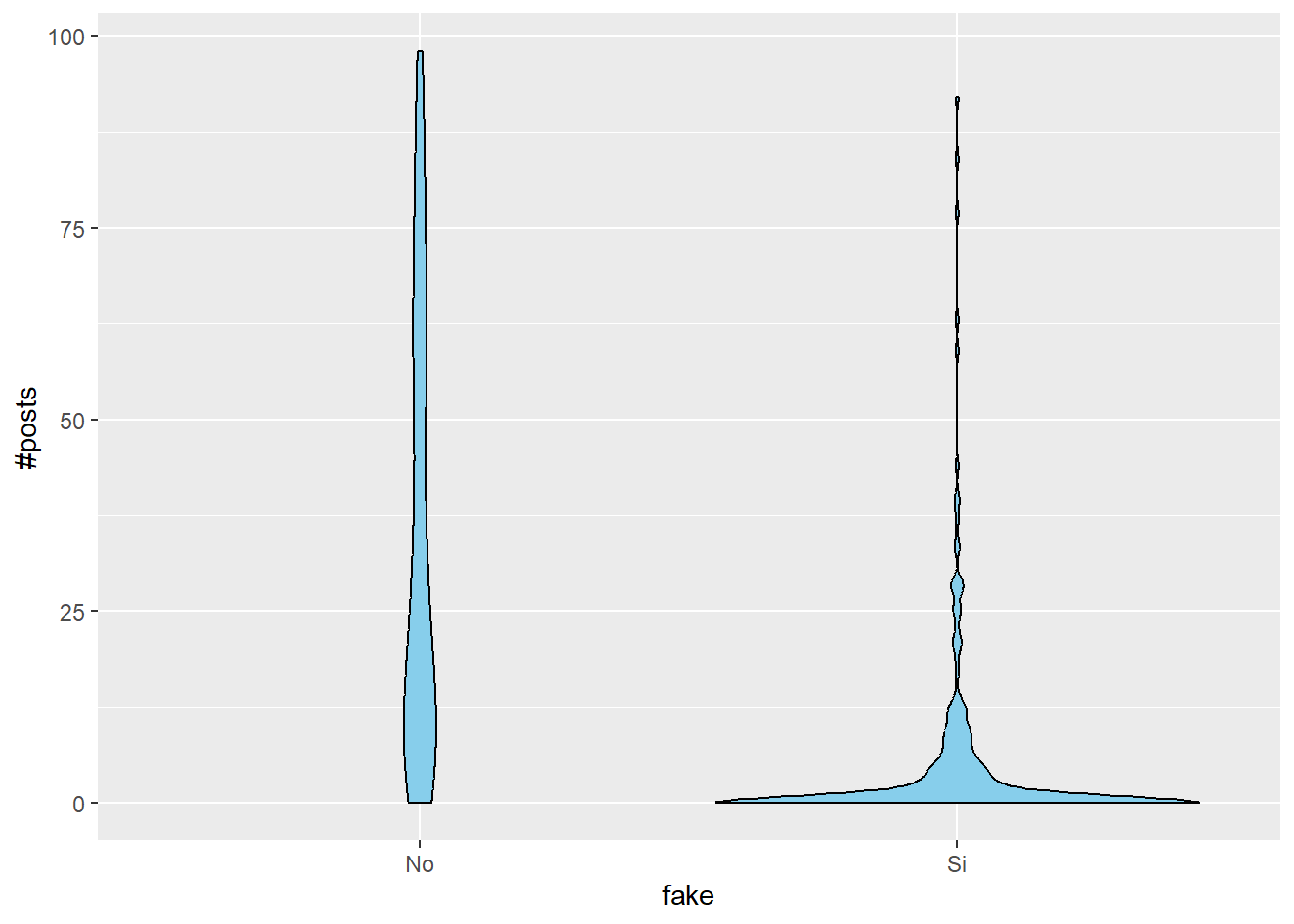
Podemos suponer una posible hipótesis en la que los usuarios spammers, cuya tarea puede ser solo generar comentarios o likes, van a tener cuentas con menos número de publicaciones que una cuenta de una persona verdadera. Vamos a visualizar esta idea:
posts_filtrados <- datos_refinados %>%filter(`#posts`<100)ggplot(posts_filtrados, aes(x = fake, y =`#posts`)) +geom_violin(fill ="skyblue", color ="black")
Observamos que teníamos razón. Después de eliminar aquellas cuentas con muchos posts, vemos que las cuentas falsas suelen tener un número reducido de publicaciones, mientras que las cuentas normales suelen tener una distribución más uniforme.
2.6 Análisis de número de seguidores.
Uno de los atributos más relevantes puede ser el número de seguidores. Por lo tanto, necesitamos analizarlo en profundidad. Vamos a comenzar con el número de seguidores.
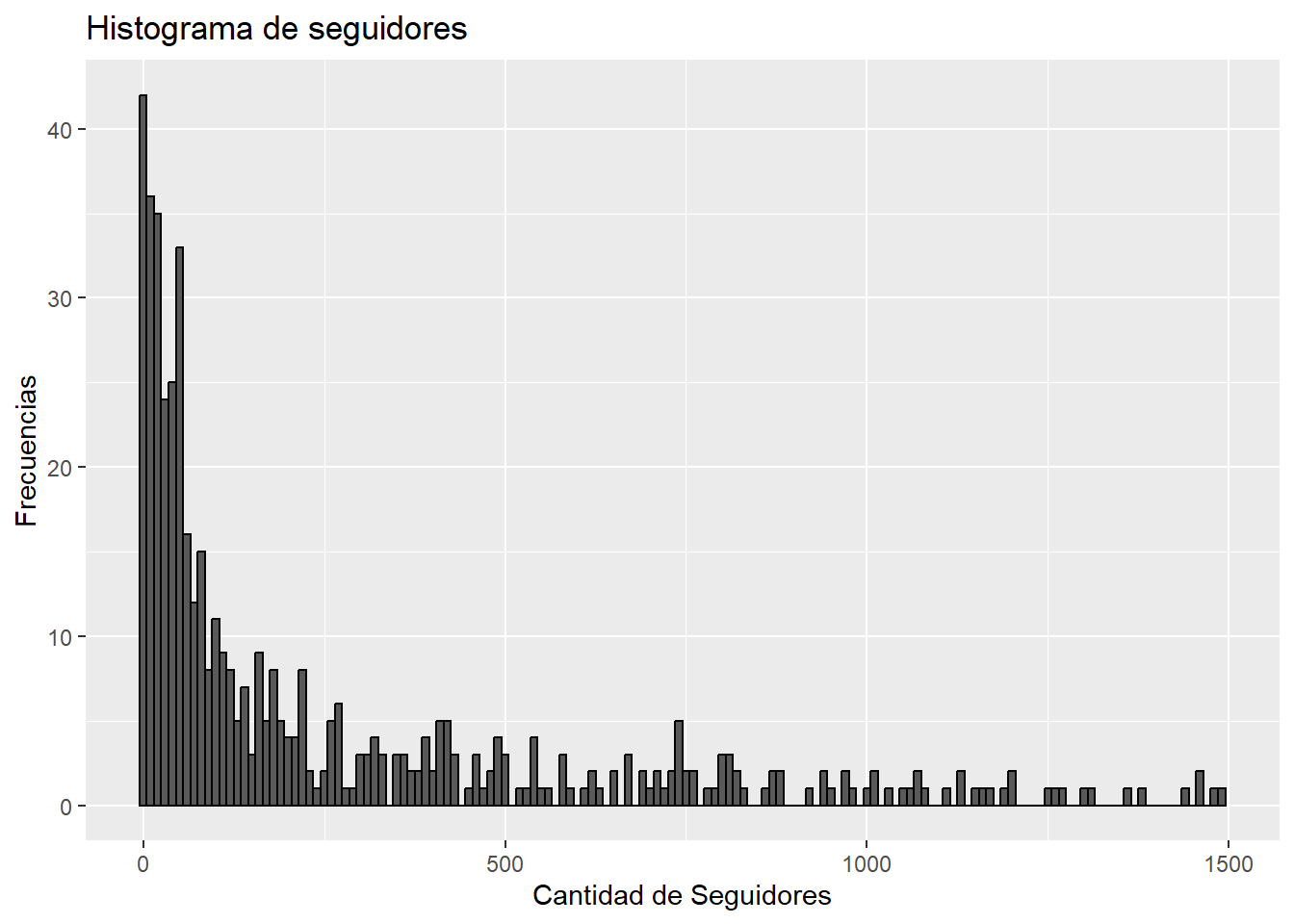
Primero, como en el análisis exploratorio observamos que había algunas cuentas con muchos seguidores pero que no representaban un número importante, vamos a eliminar esas escasas cuentas con un número alto de seguidores con el fin de que los gráficos sean más entendibles.
followers_filtrados <- datos_refinados %>%filter(`#followers`<1500)ggplot(followers_filtrados, aes(x =`#followers`)) +geom_histogram(binwidth =10, color ='black') +labs(title ="Histograma de seguidores",x ="Cantidad de Seguidores",y ="Frecuencias")
Vemos que la mayoría se concentra en menos de 250 seguidores.
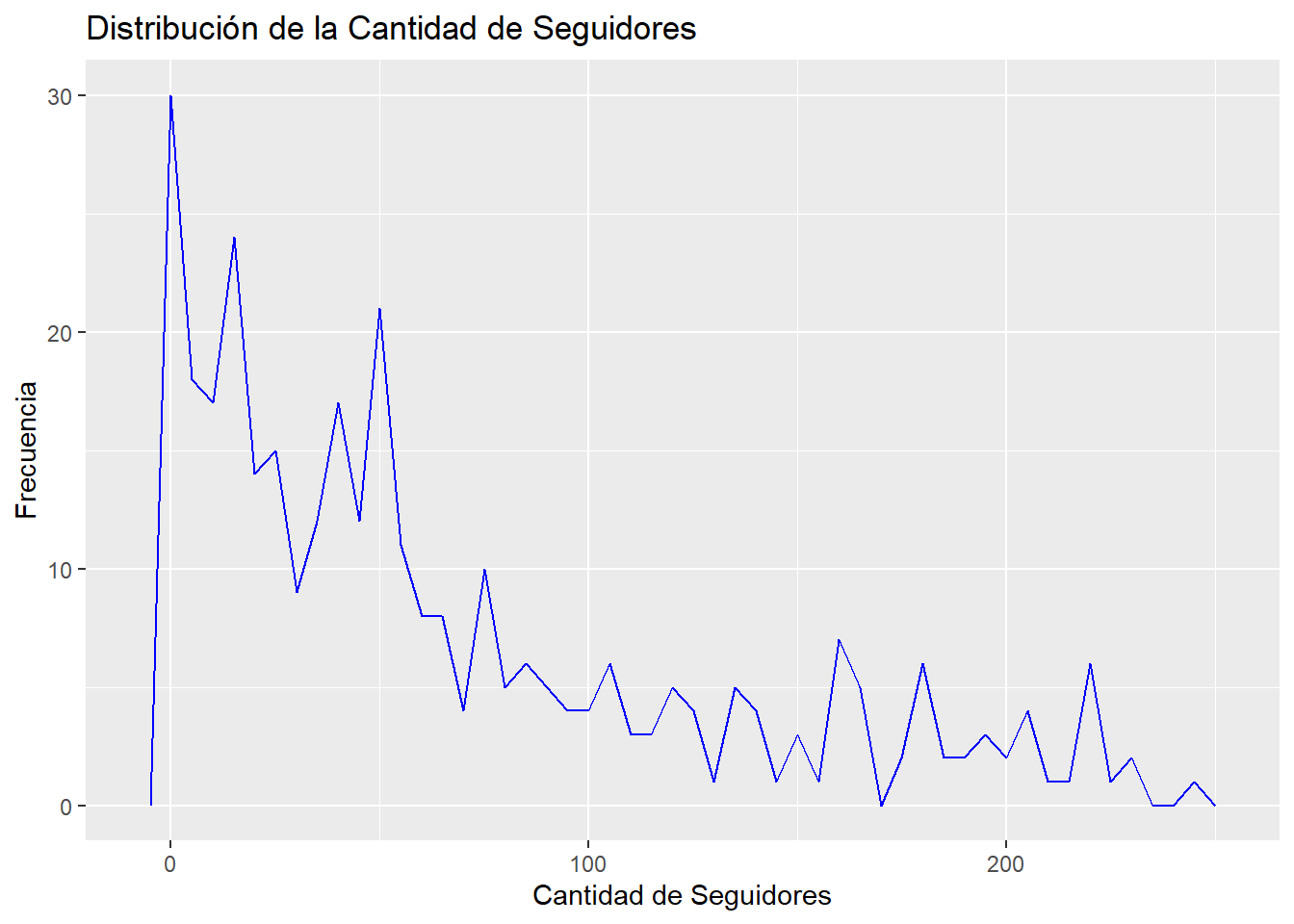
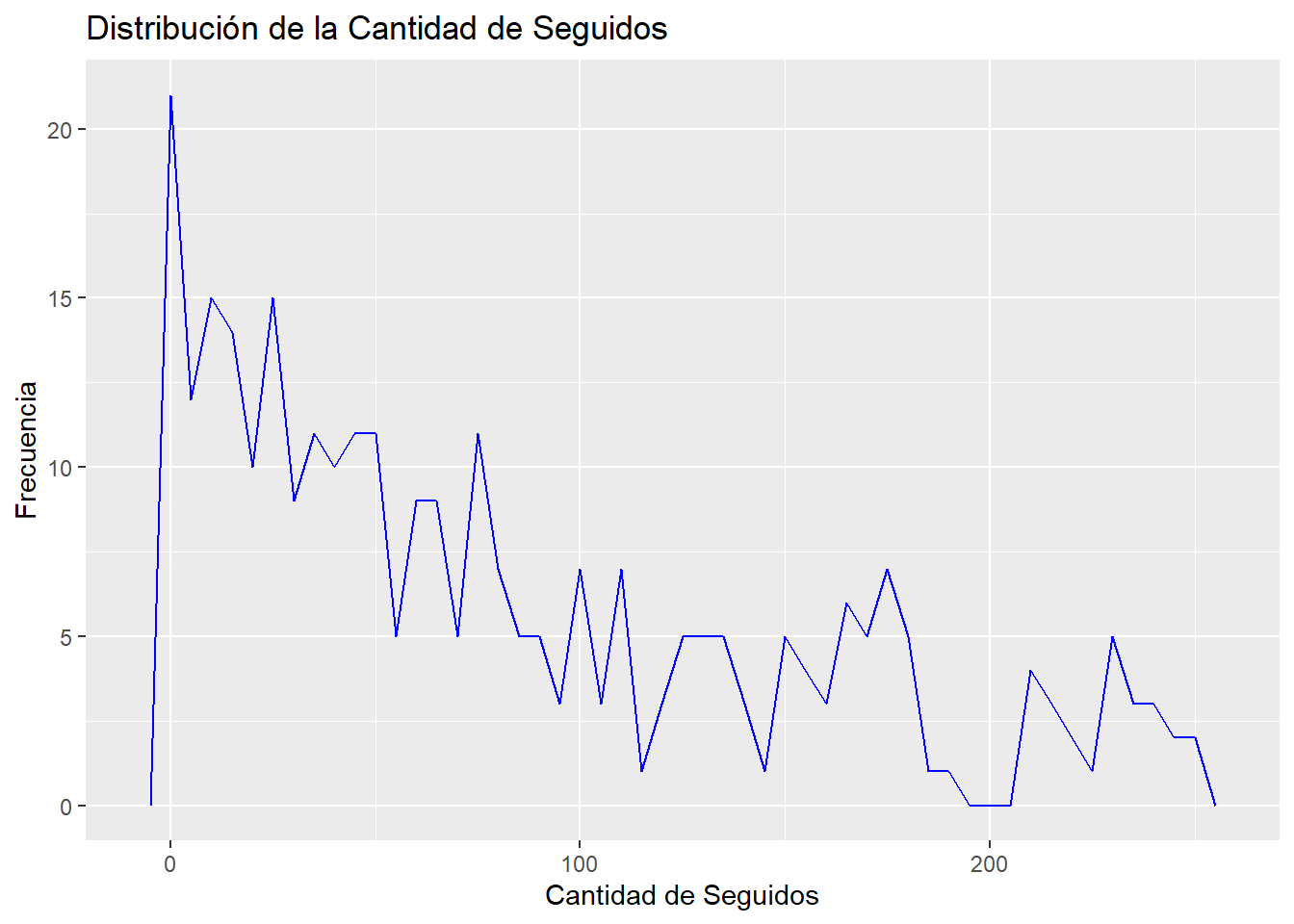
Vamos a utilizar una gráfica de frecuencia para ver cómo son nuestros datos con menos de 250 seguidores.
followers_filtrados <- datos_refinados %>%filter(`#followers`<250)ggplot(followers_filtrados, aes(x =`#followers`)) +geom_freqpoly(color ="blue", binwidth =5) +labs(title ="Distribución de la Cantidad de Seguidores",x ="Cantidad de Seguidores",y ="Frecuencia")
La mayor concentración se encuentra en menos de 100 seguidores y la frecuencia disminuye a medida que aumenta el número de seguidores.
2.7 Comparación del número de seguidores entre cuentas reales y falsas.
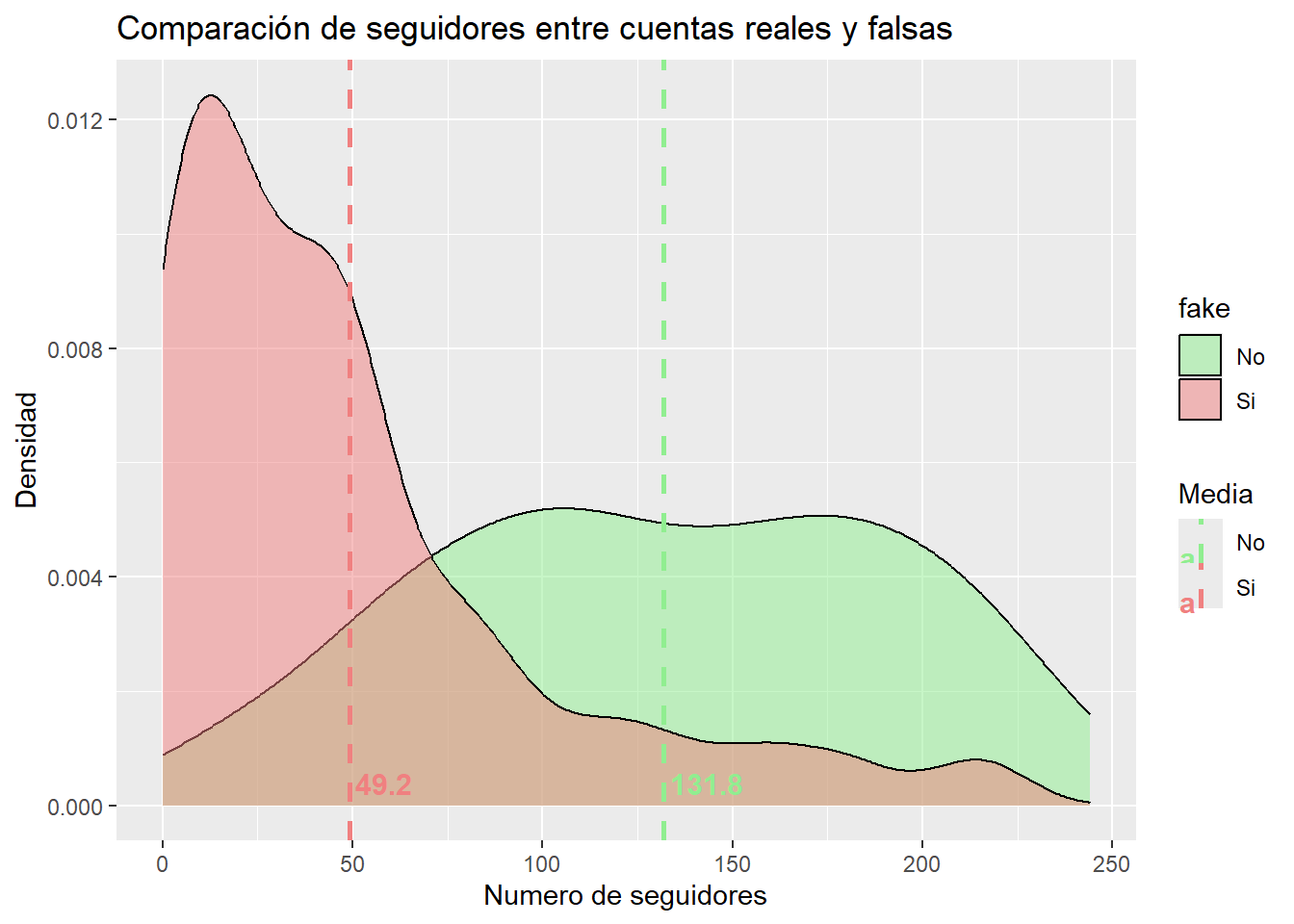
Como nuestro principal objetivo es poder encontrar características similares que tengan las cuentas falsas para poder identificarlas fácilmente, vamos a visualizar este atributo en relación con el número de seguidores. Además, añadiremos las medias para obtener más información.
mean_values <- followers_filtrados %>%group_by(fake) %>%summarize(mean_followerss =mean(`#followers`))ggplot(data = followers_filtrados, aes( x =`#followers`,fill =`fake`)) +geom_density(alpha =0.5) +labs(title ="Comparación de seguidores entre cuentas reales y falsas", x ="Numero de seguidores", y ="Densidad") +scale_fill_manual(values =c("lightgreen", "lightcoral"))+geom_vline(data = mean_values, aes(xintercept = mean_followerss, color = fake), linetype ="dashed", size =1) +geom_text(data = mean_values, aes(x = mean_followerss, y =0, label =round(mean_followerss, 1), color = fake),vjust =-0.5, hjust =-0.1, size =4, fontface ="bold") +scale_color_manual(values =c("lightgreen", "lightcoral"), name ="Media")
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
Aquí obtenemos información más interesante. Podemos observar que las cuentas falsas tienden a tener un menor número de seguidores, mientras que las cuentas reales, aunque no tienen muchos seguidores, suelen mantenerse en un intervalo entre 50 y 250. Esta información nos puede ser de importancia para los cálculos futuros.
2.8 Análisis de número de seguidos.
Ahora que hemos explorado cómo se comporta el número de seguidores según el tipo de cuentas a través de varios gráficos, vamos a continuar con el número de seguidos.
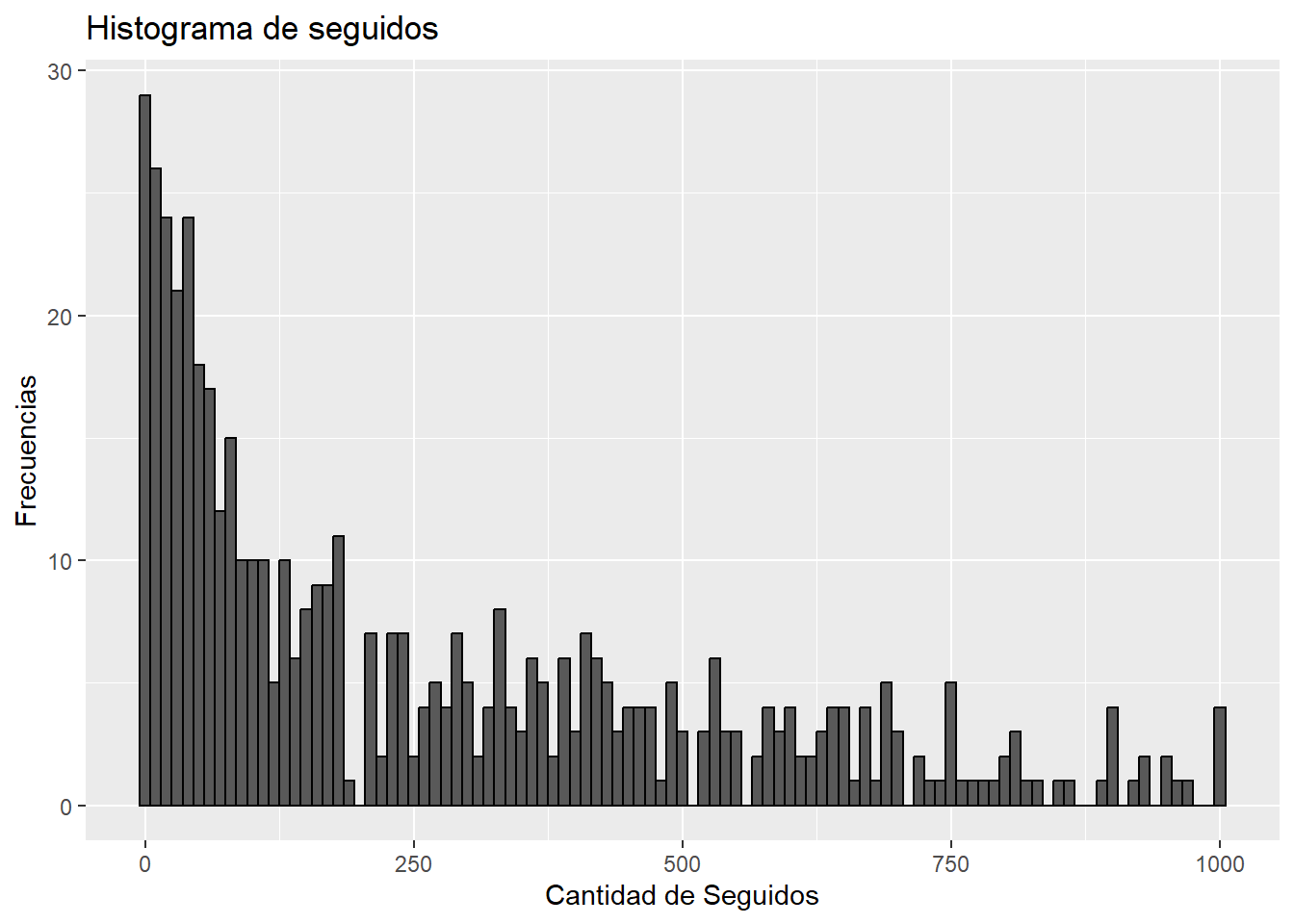
Primero, como en el análisis exploratorio observamos que había algunas cuentas con muchos seguidos, pero que no representaban un número importante, vamos a eliminar esas escasas cuentas con un número alto de seguidos con el fin de que los gráficos sean más entendibles.
follows_filtrados <- datos_refinados %>%filter(`#follows`<1000) ggplot(follows_filtrados, aes(x =`#follows`)) +geom_histogram(binwidth =10, color ='black') +labs(title ="Histograma de seguidos", x ="Cantidad de Seguidos", y ="Frecuencias")
Vemos que la mayoría se concentra en menos de 250 seguidos.
Vamos a utilizar una gráfica de frecuencia para ver cómo son nuestros datos con menos de 250 seguidos.
follows_filtrados <- datos_refinados %>%filter(`#follows`<250) ggplot(follows_filtrados, aes(x =`#follows`)) +geom_freqpoly(color ="blue", binwidth =5) +labs(title ="Distribución de la Cantidad de Seguidos", x ="Cantidad de Seguidos", y ="Frecuencia")
La mayor concentración se encuentra en menos de 100 seguidos y la frecuencia disminuye a medida que aumenta el número de seguidos.
2.9 Comparación del número de seguidos entre cuentas reales y falsas.
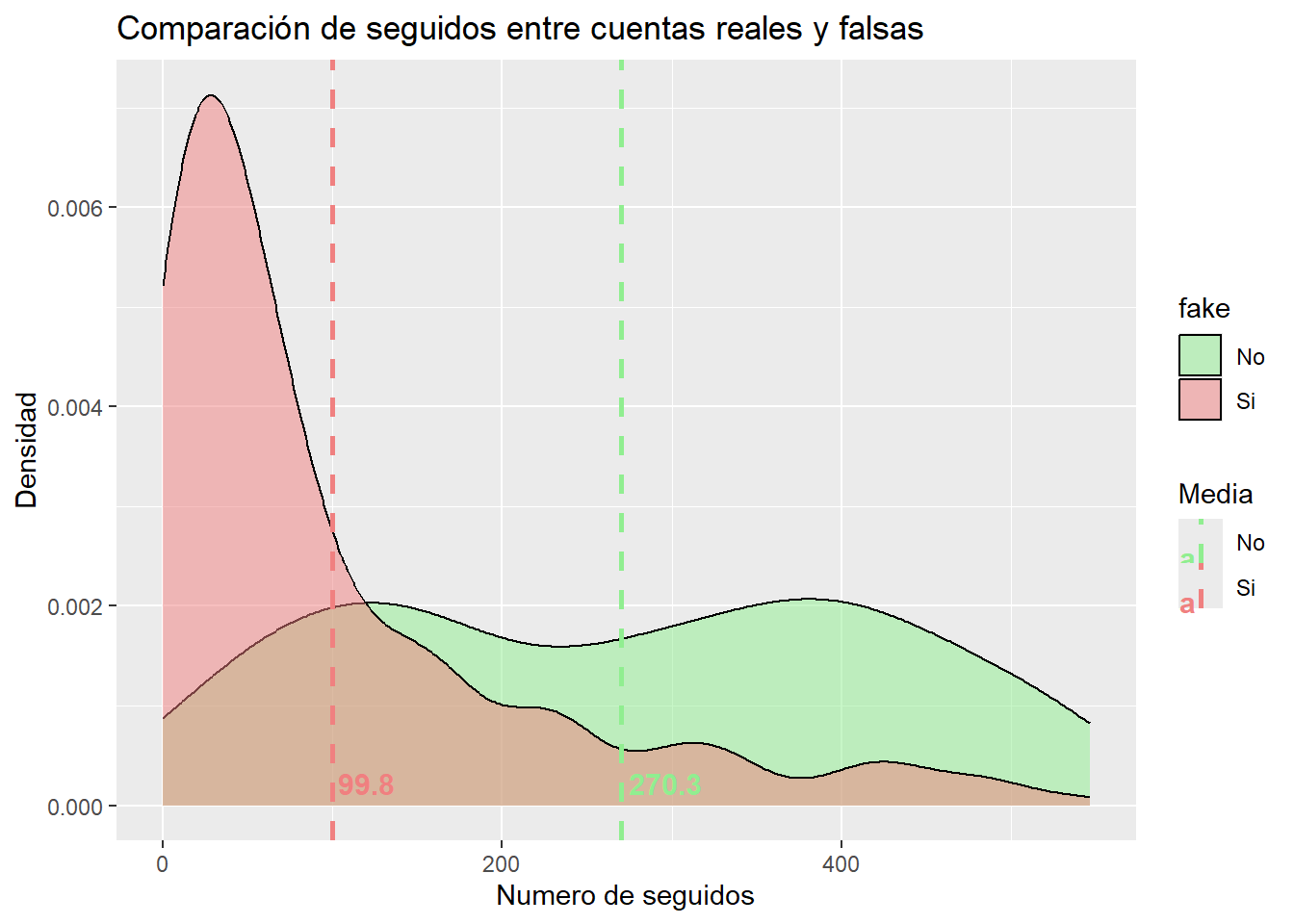
Como nuestro principal objetivo es poder encontrar características similares que tengan las cuentas falsas para poder identificarlas fácilmente, vamos a visualizar este atributo. Además, añadiremos las medias para obtener más información.
follows_filtrados <- datos_refinados %>%filter(`#follows`<550) mean_values <- follows_filtrados %>%group_by(fake) %>%summarize(mean_follows =mean(`#follows`))ggplot(data = follows_filtrados, aes( x =`#follows`,fill =`fake`)) +geom_density(alpha =0.5) +labs(title ="Comparación de seguidos entre cuentas reales y falsas", x ="Numero de seguidos", y ="Densidad") +scale_fill_manual(values =c("lightgreen", "lightcoral"))+geom_vline(data = mean_values, aes(xintercept = mean_follows, color = fake), linetype ="dashed", size =1) +geom_text(data = mean_values, aes(x = mean_follows, y =0, label =round(mean_follows, 1), color = fake),vjust =-0.5, hjust =-0.1, size =4, fontface ="bold") +scale_color_manual(values =c("lightgreen", "lightcoral"), name ="Media")
Aquí, al igual que con los seguidores, obtenemos información más interesante. Podemos observar que las cuentas falsas tienden a tener un menor número de seguidores, pero no tan cercano a 0, mientras que las cuentas reales suelen tener un número más repartido de seguidos. Esta información nos puede ser de importancia para los cálculos futuros.
2.10 Relación entre número de seguidores y número de seguidos.
Ahora que hemos visto ambas variables por separado, vamos a utilizar gráficos de puntos o dispersión para ver varias variables juntas e intentar encontrar alguna relación o característica en estas.
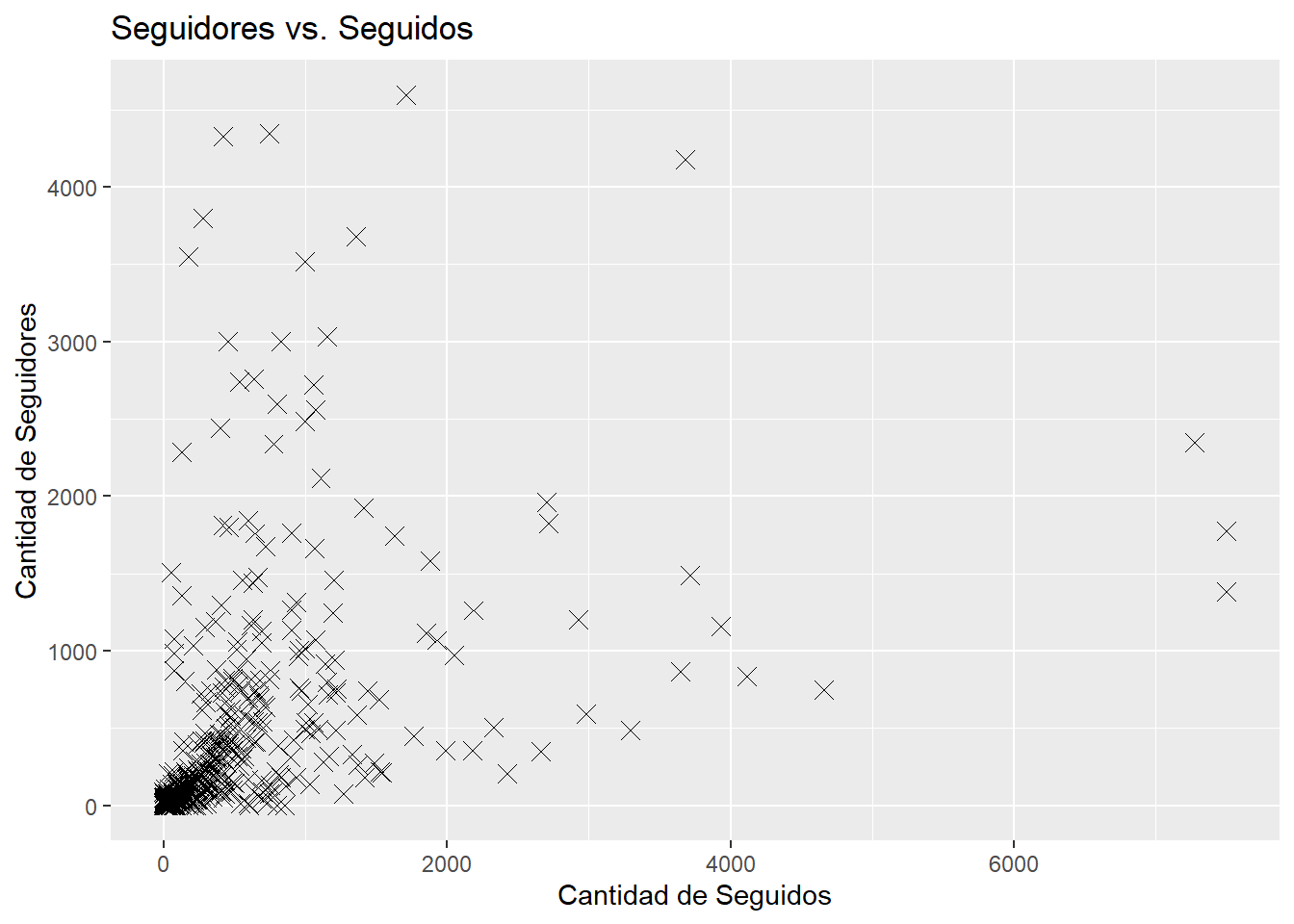
followers_filtrados <- datos_refinados %>%filter(`#followers`<5000)ggplot(data = followers_filtrados, aes(x =`#follows`, y =`#followers`)) +geom_point(shape =4, size =3) +labs(title ="Seguidores vs. Seguidos",x ="Cantidad de Seguidos",y ="Cantidad de Seguidores")+scale_fill_manual(values =c("skyblue", "lightcoral"))
Viendo este gráfico, solo podemos observar que casi todo se concentra en un número reducido tanto de seguidos como de seguidores.
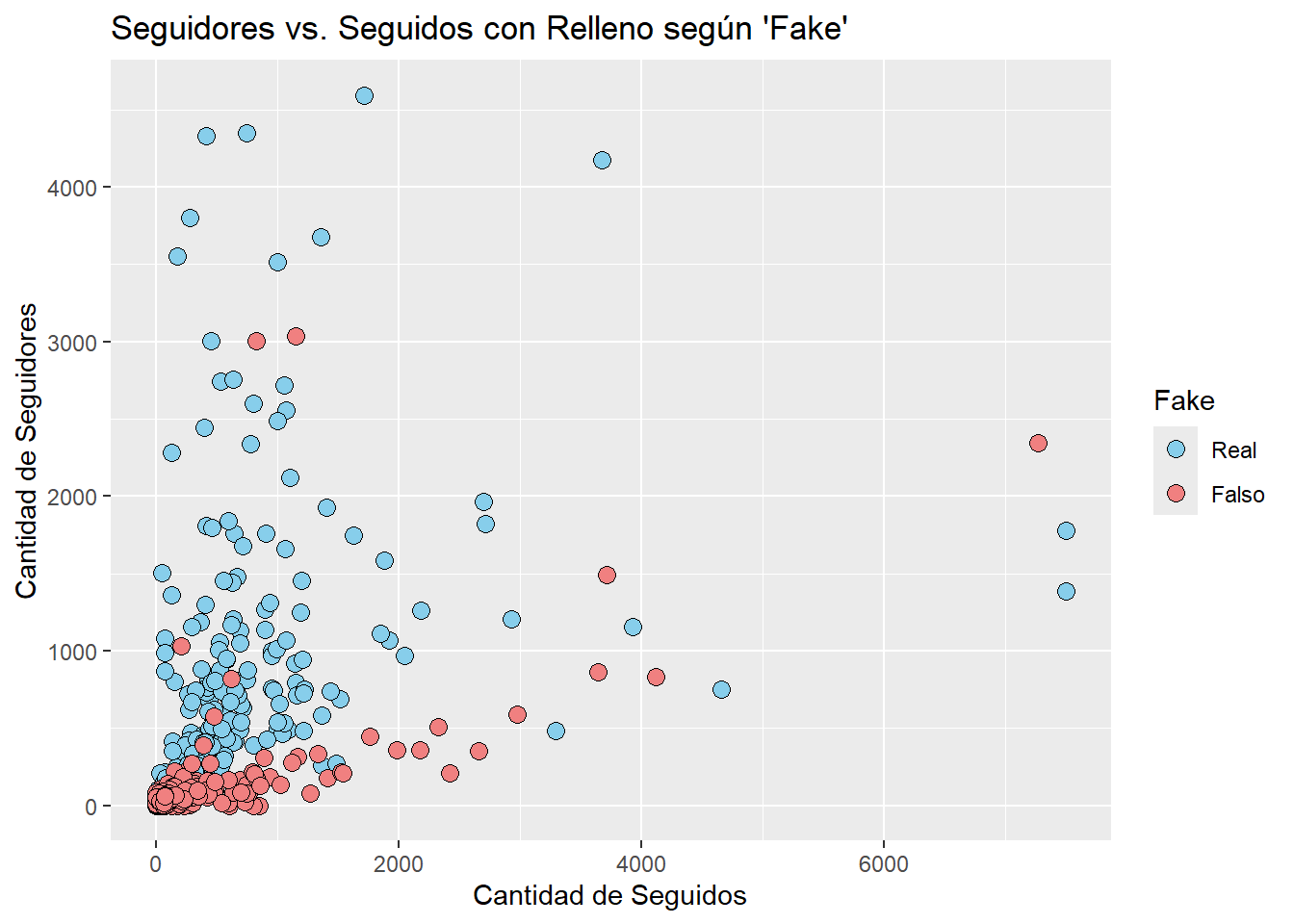
Aunque dicha información no nos sea de mucha utilidad, vamos a añadir el parámetro para diferenciar cuentas falsas y reales. Podemos pensar que los seguidores y los seguidos tienen alguna relación con los usuarios que son falsos. Vamos a refinar un poco el DataSet eliminando los usuarios que tenían muchos seguidores. Vamos a investigar:
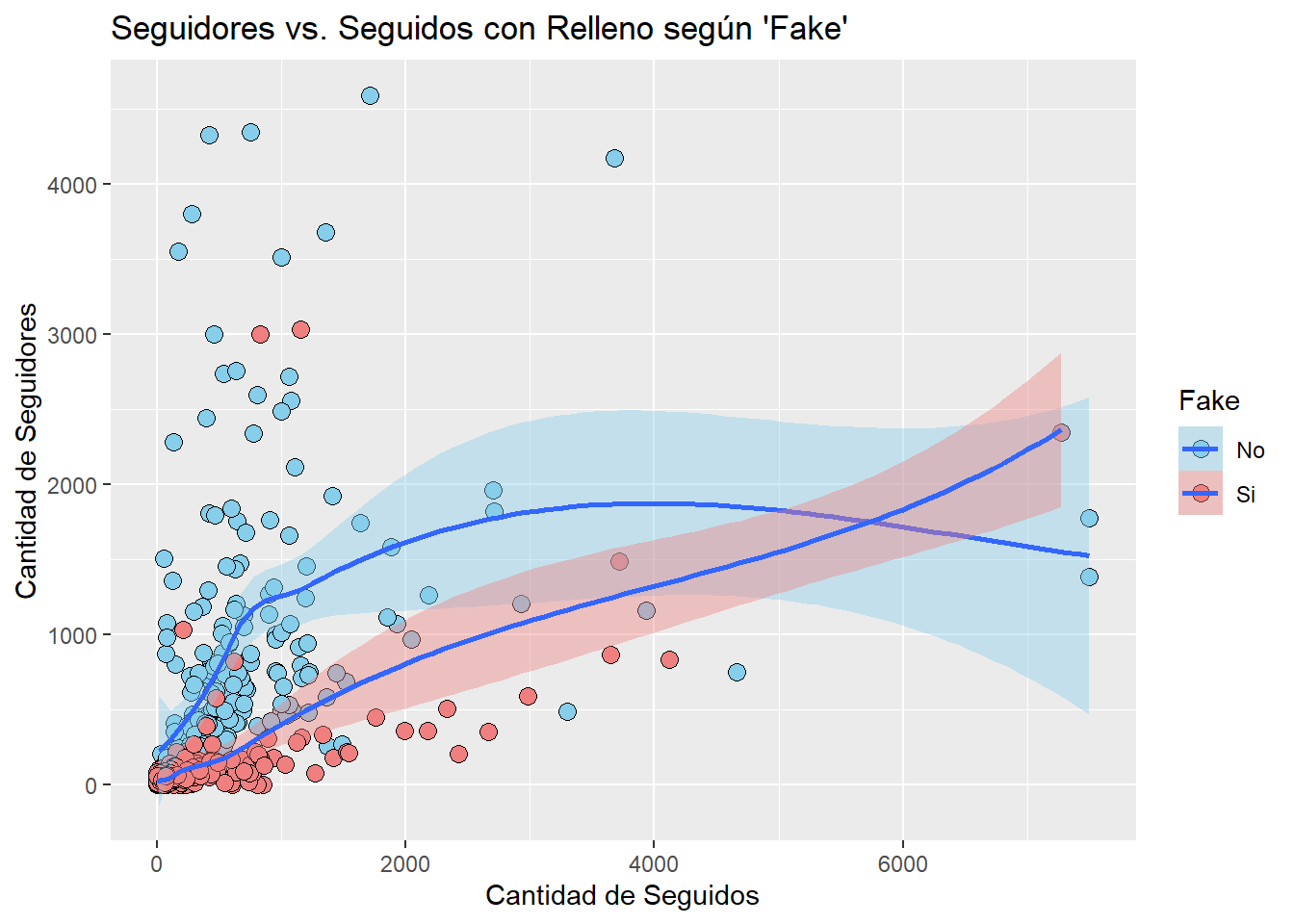
followers_filtrados <- datos_refinados %>%filter(`#followers`<5000)ggplot(data = followers_filtrados, aes(x =`#follows`, y =`#followers`, fill =fake)) +geom_point(shape =21, size =3) +labs(title ="Seguidores vs. Seguidos con Relleno según 'Fake'",x ="Cantidad de Seguidos",y ="Cantidad de Seguidores",fill ="Fake") +scale_fill_manual(values =c("skyblue", "lightcoral"), labels =c("Real", "Falso"))
Aquí podemos ver que hay una cierta tendencia. Las cuentas falsas suelen tener más cuentas seguidas que seguidores. Esto puede ser debido a que al ser cuentas generadas automáticamente, seguir a otras cuentas es una tarea que se puede automatizar, mientras que conseguir seguidores es algo más complicado y requiere de una acción activa por parte de otra persona para seguir la cuenta. Vamos a utilizar el atributo de geom_smooth para poder visualizar una posible tendencia.
ggplot(data = followers_filtrados, aes(x =`#follows`, y =`#followers`, fill = fake)) +geom_point(shape =21, size =3) +geom_smooth(method ="loess")+labs(title ="Seguidores vs. Seguidos con Relleno según 'Fake'",x ="Cantidad de Seguidos",y ="Cantidad de Seguidores",fill ="Fake") +scale_fill_manual(values =c("skyblue", "lightcoral") )
`geom_smooth()` using formula = 'y ~ x'
Ahora podemos reafirmar la idea de esa posible tendencia gracias a este gráfico. Vemos que los puntos rojos (falsos) se ajustan a la línea roja. Sin embargo, las cuentas verdaderas tienen una tendencia más dispersa.
2.11 Importancia de la presencia de caracteres numéricos en el usuario y nombre.
Encontrar caracteres numéricos en el nombre de usuario y en los nombres completos es algo que, a primera vista, no podemos asociar con ningún tipo de cuenta. Por lo tanto, nos vemos en la necesidad de analizarlo más en profundidad.
#Tenemos que duplicar los datos para poder poner una grafica al lado de otra#Pivot_longer elimina las columnas conbinandola en dos columnas con el nombre y el valorlibrary(tidyr)
Attaching package: 'tidyr'
The following object is masked from 'package:magrittr':
extract
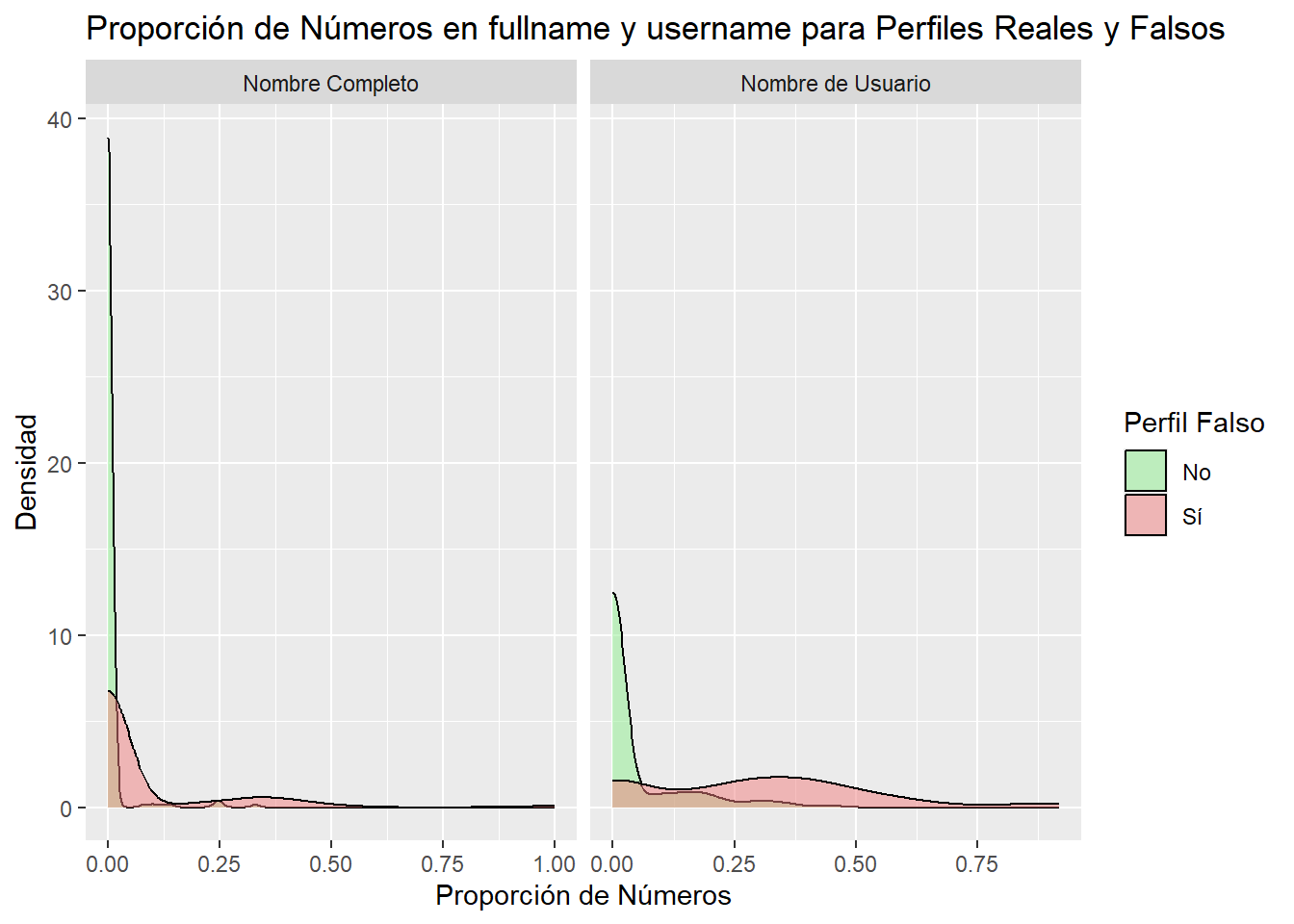
datos_comb <- datos_refinados %>%pivot_longer(cols =c(`nums/length fullname`, `nums/length username`), names_to ="variable", values_to ="value")ggplot(data = datos_comb, aes(x = value, fill = fake)) +geom_density(alpha =0.5, adjust =1) +labs(title ="Proporción de Números en fullname y username para Perfiles Reales y Falsos",x ="Proporción de Números",y ="Densidad",fill ="Perfil Falso") +scale_fill_manual(values =c("lightgreen", "lightcoral"), labels =c("No", "Sí")) +facet_wrap(~variable, scales ="free_x", labeller =as_labeller(c(`nums/length fullname`="Nombre Completo", `nums/length username`="Nombre de Usuario")))
Podemos ver que realmente hay una relación entre la presencia de caracteres numéricos en el nombre y el nombre de usuario con respecto a si la cuenta es verdadera o spammer.
Podemos concluir que las cuentas falsas suelen contener un mayor número de caracteres numéricos en el nombre o nombre de usuario que las cuentas verdaderas.
2.12 Relación entre longitud de la descripción para perfiles reales y perfiles falsos.
Por último, otra posible hipótesis podría ser que los usuarios falsos tienen descripciones vacías o menos elaboradas que las de los perfiles reales.
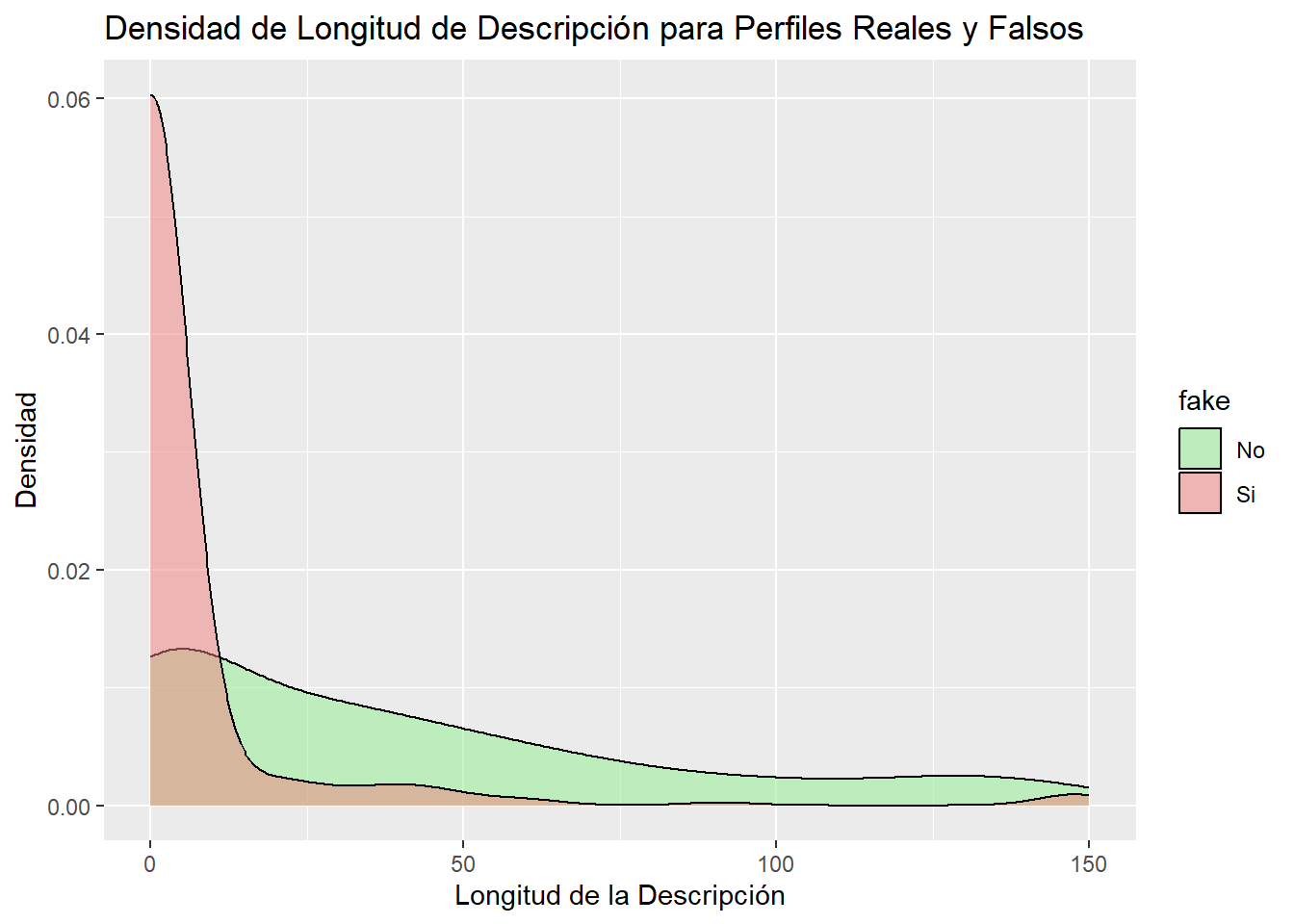
ggplot(data = datos_refinados, aes(x =`description length`, fill = fake)) +geom_density(alpha =0.5) +labs(title ="Densidad de Longitud de Descripción para Perfiles Reales y Falsos",x ="Longitud de la Descripción",y ="Densidad") +scale_fill_manual(values =c("lightgreen", "lightcoral"))
Y podemos comprobar que dicha idea era cierta. Los perfiles falsos suelen tener un número reducido de caracteres en su descripción, mientras que los perfiles reales están más repartidos.
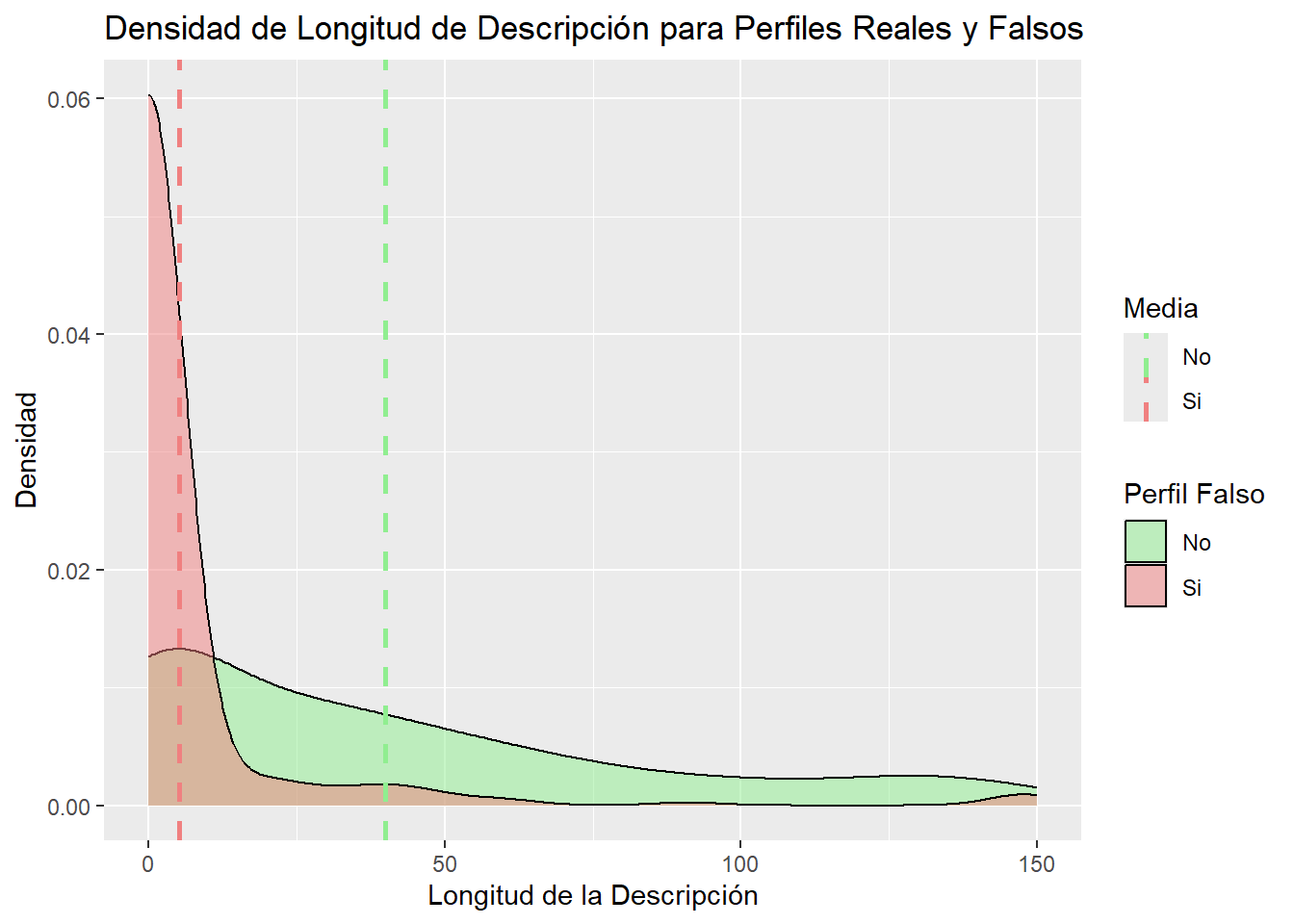
Vamos a visualizar las medias:
mean_values <- datos_refinados %>%group_by(fake) %>%summarize(mean_desc_length =mean(`description length`))ggplot(data = datos_refinados, aes(x =`description length`, fill =fake)) +geom_density(alpha =0.5) +labs(title ="Densidad de Longitud de Descripción para Perfiles Reales y Falsos",x ="Longitud de la Descripción",y ="Densidad",fill ="Perfil Falso") +scale_fill_manual(values =c("lightgreen", "lightcoral"))+geom_vline(data = mean_values, aes(xintercept = mean_desc_length, color = fake), linetype ="dashed", size =1) +scale_color_manual(values =c("lightgreen", "lightcoral"), name ="Media")
2.13 Conclusiones:
Las cuentas falsas tienden a tener un menor número de seguidores y un mayor número de seguidos.
Las cuentas reales tienen descripciones con longitudes más largas en comparación con las cuentas falsas.
Las cuentas falsas tienen una mayor cantidad de caracteres numéricos en el nombre completo y nombre de usuario en comparación con las cuentas reales.
Las cuentas reales suelen tener foto de perfil, mientras que las cuentas falsas pueden carecer de ella en muchos casos.