Vamos a utilizar reglas de asociación para detectar cuentas falsas en Instagram. Este método nos permitirá descubrir relaciones interesantes entre diferentes características observadas en el dataset. Utilizaremos el paquete arules para llevar a cabo estas operaciones.
3.1 Características importantes:
3.1.1Medidas relevantes
Para evaluar la calidad y relevancia de las reglas de asociación, utilizaremos las siguientes medidas:
Soporte (Support): Mide la proporción de cuentas en el dataset que contienen ambos conjuntos de características A y B. Un alto soporte indica que la regla se aplica a una gran proporción del dataset, lo que sugiere que la combinación de características es común y relevante.
Confianza (Confidence): Mide cuán frecuentemente las características en B aparecen en las cuentas que contienen A. Una mayor confianza indica una mayor fiabilidad de que la presencia de las características en A implicará la presencia de las características en B.
Elevación (Lift): Mide la relación entre la aparición conjunta de A y B y la aparición esperada de A y B si fueran independientes. Una elevación alta (mayor que 1) indica que la presencia de A incrementa significativamente la probabilidad de que B ocurra, lo que sugiere una fuerte asociación entre las características.
3.1.2Algoritmo Apriori
Utilizaremos el algoritmo Apriori para obtener reglas a partir de nuestros datos. Este algoritmo se basa en la propiedad de que cualquier subconjunto de un conjunto frecuente también debe ser frecuente. Itera a través de los conjuntos de características, incrementando su tamaño en cada iteración y manteniendo solo los conjuntos que cumplen con un umbral mínimo de soporte.
3.1.3Reglas
Las reglas de asociación consisten en implicaciones del tipo “Si A entonces B”, donde A y B son conjuntos de características o comportamientos de las cuentas. Por ejemplo, una regla podría ser “Si una cuenta tiene un número alto de cuentas seguidas y no tiene foto de perfil, entonces es probable que sea una cuenta falsa”.
3.2Carga de datos:
Vamos a cargar las librerías necesarias y nuestro dataset.
library(arules)
Loading required package: Matrix
Attaching package: 'arules'
The following objects are masked from 'package:base':
abbreviate, write
library(arulesViz)
Warning: package 'arulesViz' was built under R version 4.3.3
library(readr)datos <-read_csv("Data/train.csv")
Rows: 576 Columns: 12
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (12): profile pic, nums/length username, fullname words, nums/length ful...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
3.3 Discretizar datos
Puesto que el algoritmo de apriori necesita que el conjunto de datos sea binario o discreto.
Existen varias formas de discretizar datos, pero el objetivo principal es convertir las características continuas en valores discretos que representen de manera efectiva la información subyacente. Algunas técnicas comunes de discretización incluyen la binarización, la división en intervalos fijos o basados en cuantiles.
Tras haber realizado el previo análisis exploratorio podemos definir intervalos personalizados para cada variable, para ello usaremos las funciones ordered y cut. Además, las variables que son binarias como “fake”, vamos a ponerles “Si” o “No” para poder comprenderlas mejor.
Esta función del paquete de arules implementa varios métodos básicos no supervisados para convertir una variable continua en una variable categórica (factor) usando diferentes estrategias de agrupamiento.
Vamos a quitar primero las columnas binarias a las que queremos asignar un valor personalizado.
# A tibble: 6 × 12
`profile pic` `nums/length username` `fullname words` `nums/length fullname`
<fct> <fct> <fct> <fct>
1 Si medio muy bajo muy bajo
2 Si muy bajo medio muy bajo
3 Si bajo medio muy bajo
4 Si muy bajo bajo muy bajo
5 Si muy bajo medio muy bajo
6 Si muy bajo alto muy bajo
# ℹ 8 more variables: `name==username` <fct>, `description length` <fct>,
# `external URL` <fct>, private <fct>, `#posts` <fct>, `#followers` <fct>,
# `#follows` <fct>, fake <fct>
# A tibble: 6 × 12
`profile pic` `nums/length username` `fullname words` `nums/length fullname`
<fct> <fct> <fct> <fct>
1 Si bajo muy bajo muy bajo
2 Si muy bajo muy bajo muy bajo
3 Si muy bajo muy bajo muy bajo
4 Si muy bajo muy bajo muy bajo
5 Si muy bajo muy bajo muy bajo
6 Si muy bajo bajo muy bajo
# ℹ 8 more variables: `name==username` <fct>, `description length` <fct>,
# `external URL` <fct>, private <fct>, `#posts` <fct>, `#followers` <fct>,
# `#follows` <fct>, fake <fct>
3.4 Generar dataset de transacciones
Ahora, una vez discretizado el dataframe, el siguiente paso es generar un dataset de transacciones. Este tipo de dataset es esencial para aplicar algoritmos de reglas de asociación como Apriori.
En un dataset de transacciones, cada fila representa una transacción, que es una colección de elementos o ítems.
Ahora que ya tenemos todo listo, podemos utilizar los algoritmos de generación de reglas. En nuestro caso, vamos a utilizar Apriori. Para generar reglas primero necesitamos establecer un valor para el soporte y confianza mínima, estos valores nos permitirán controlar la cantidad y calidad de las reglas que se generarán.
Hemos obtenido una buena cantidad de reglas para continuar nuestro análisis.
3.6 Refinar reglas
Ahora que hemos obtenido las reglas, necesitamos cribarlas y eliminar todas aquellas que no nos interesan, que sean redundantes o no significativas.
3.6.1 Eliminar reglas redundantes
rules <- rules[which(is.redundant(rules))]
3.6.2 Eliminar reglas no significativas
rules <- rules[which(is.significant(rules))]
Vamos a ver cuentas reglas han quedado después de filtrarlas:
length(rules)
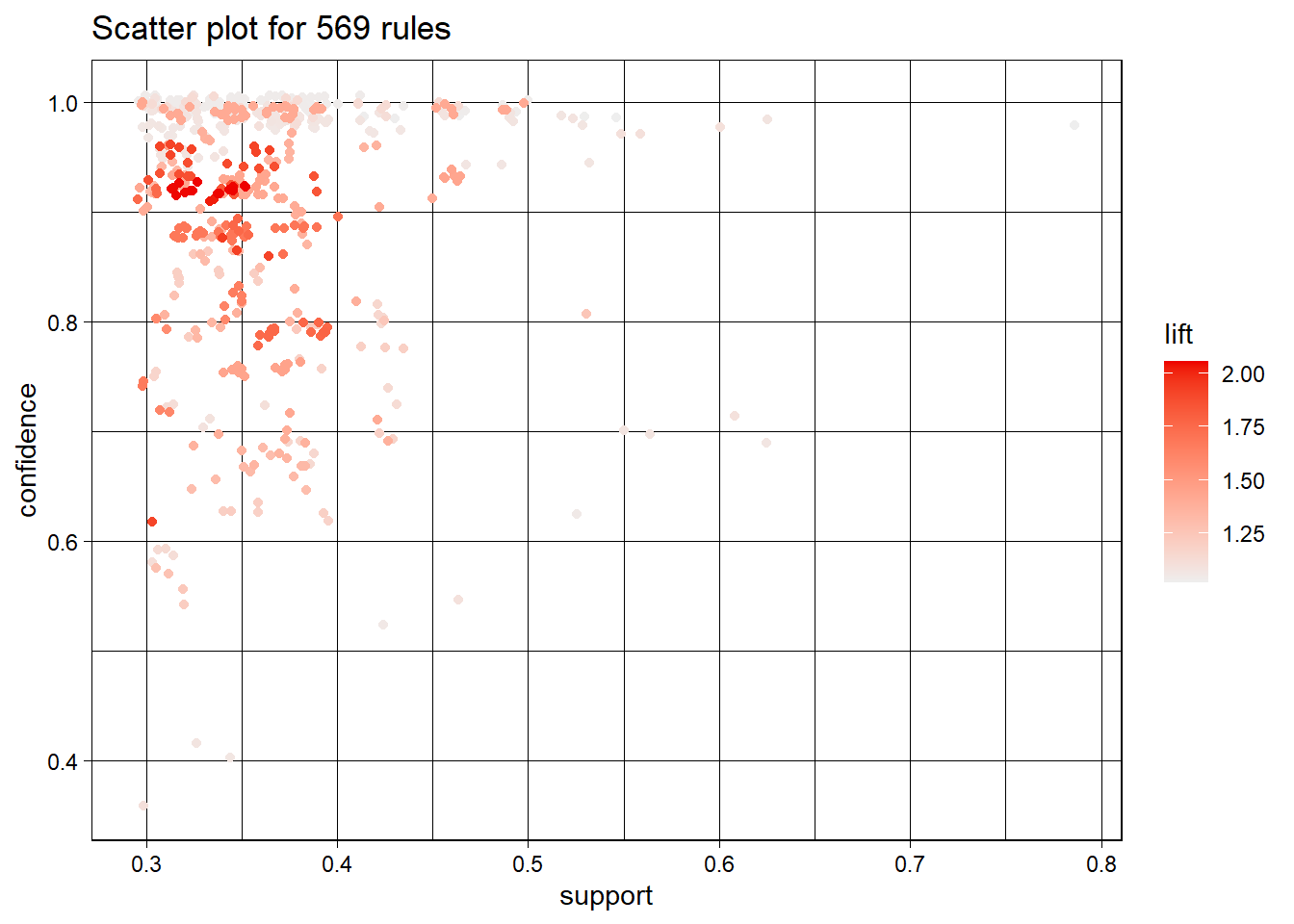
[1] 569
3.7 Análisis de reglas obtenidas
Nuestro objetivo es detectar y diferenciar cuentas falsas de las verdaderas, por lo tanto, vamos a centrar nuestro análisis en esos dos atributos: “fake=Si” y “fake=No”. Como tenemos diferentes métricas, vamos a analizarlas por separado:
3.7.1 Soporte
Vamos primero a analizar las reglas ordenándolas por el soporte. Recordamos que un soporte alto indica que la regla se aplica a una gran proporción del dataset, lo que sugiere que la combinación de características es común y relevante.
En este caso, el soporte es 0.7881944, lo que significa que el 78.82% de las transacciones en el dataset contienen tanto el antecedente {nums/length fullname=muy bajo, external URL=No} como el consecuente {name==username=No}.
Ahora vamos a analizar las reglas ordenándolas por la confianza. Recordamos que a mayor confianza, mayor es la fiabilidad de que la presencia de las características en el antecedente de la regla A implicará la presencia de las características en el consecuente de la regla B.
Por último, vamos a analizar las reglas ordenándolas primero por el lift de las reglas. Recordamos que un lift alto indica que la presencia de A incrementa significativamente la probabilidad de que B ocurra, lo que sugiere una fuerte asociación entre las características.
En este caso, el lift es 2.059, lo que sugiere que la aparición de “external URL=Si” es aproximadamente 2 veces más probable cuando se dan las condiciones en el antecedente.